¿Cómo es posible escribir Japonés con un teléfono móvil? - Parte 1( Por Kirai )
¿Cómo es posible escribir Japonés con un teléfono móvil? - Parte 1
Para poder entender esta entrada haber leído antes el Sistema de escritura Japonés.
El problema fundamental del japonés que debéis de mantener en mente durante la lectura de este artículo es que para una sílaba, por ejemplo KI, existen muchas maneras de representarla, por ejemplo:樹、来、木、機、匱… Un humano es capaz de saber por el conexto y por lo que quiere escribir cual de los Kanjis quiere utilizar para el sonido KI, pero en cambio para dispositivo automático no es una tarea tan sencilla. Lo mismo pasa con el Chino.
Con algo más de 15 teclas es posible escribir japonés, un idioma con más de 2000 caracteres de uso cotidiano. Con un ordenador el problema es algo más sencillo, pero aun así nos tenemos que apañar con un sistema de entrada de unas cuantas decenas de teclas para conseguir una salida de varios miles de letras. Pues resulta que después de muchos años comiéndose el coco, los japoneses tienen teléfonos móviles con los que puedo escribir en Japonés mucho más rápido que en mi propio idioma, el español.
Con esta entrada espero responder a las típicas preguntas ¿Cómo son los teclados japoneses? ¿Cómo es posible escribir japonés en un ordenador? ¿Cómo escriben los chinos que aun tienen más símbolos que en Japón?
Voy a hablar en general de cómo se solucionó el problema de los “sistemas de entrada/input” de idiomas CJK (Chinese-Japanese-Korean). Que no hay que confundir con otro problema muy distinto que es el de la representación en memoria y en pantalla de “salida/output de caracteres” de idiomas CJK; un problema que en principio tecnológicamente es mucho más sencillo de solucionar pero para el que hace falta que TODO EL MUNDO se ponga de acuerdo. Algo que se está intentando conseguir gracias a Unicode.
La imprenta fue el primer método de entrada/salida medianamente automatizado de la historia. Crear un sistema de entrada para una imprenta japonesa es un problema que se soluciona “simplemente” añadiendo más tipos a la colección. Seguramente en esa época chinos y japoneses acabarían locos buscando el caracteres para escribir unas pocas páginas.
Tipos para imprenta.
Miles de caractere y japoneses buscando los que necesitan. ¡Tarea de chinos! Estas dos fotos las saqué el otro día en una tienda que está en la planta B1 de Parco en Shibuya en una esquina recóndita, por si alguien está interesado en aficionarse
En los años 20, un inventor Japonés creó la primera máquina de escribir japonesa medianamente automática. Para conseguirlo utilizó un mecanismo totalmente diferente al de las máquinas tradicionales occientales para que pudiera manejar muchas más teclas. Estudió la frecuencia de uso de cada caracter a partir de escritos en periódicos nacionales y ordenó los 2400 caracteres más usados para crear el primer teclado japonés de la historia. Para utilizar su invento hacía falta un entrenamiento especial y aun así escribir con ella era lento y pesado.
Máquina de escribir japonesa con más de 2000 teclas que produjo Canon (Se conserva una en el museo de la ciencia de Ueno)Canon y Toshiba entre otras produjo estos trastos, que se usaron en empresas, en La Segunda Guerra Mundial, en instituciones del gobierno y poco más. Las máquinas de escribir mecánicas nunca llegaron al hogar común en Japón y la gente de a pie escribió “a mano” hasta los años 80.
Esto es una gran p***** porque Japón entró en la era de la computación sin poder introducir texto en su propio idioma. Durante los años 50 se apañaron con teclados occidentales para programar en Fortran, ejecutar comandos y poco más. Pero, en los 60 comenzaron a verlo negro. Varias universidades se unieron a NTT y se pusieron manos a la obra. El problema a solucionar era el de convertir una entrada de Hiragana/Katakana(Que solo son cincuenta y pico caracteres) a una salida de Kanjis(varios miles). Lo intentaron durante varios años intentando convertir frases enteras escritas mediante un teclado Katakana a Kanjis, pero solo consiguieron sistemas con tasas de error en la conversión mayores al 90%. Lo que si desarrollaron fueron menús que mostraban todos los kanjis posibles para un Kana(Hiragana, Katakana), de esta forma era posible escribir con kanjis pero muy muy lentamente. Por ejemplo, si escribimos “KIき” (1 pulsación con un teclado Kana(Hiragana, Katakana) de 50 teclas o 2 pulsaciones con un teclado occidental) aparece un menú con todos los Kanjis cuya pronunciación es KI, el resultado es que el menú se reduce de los más de 2000 Kanjis que tendría un menú convencional a una media de (2229Kanjis/50Kanas)=45 Kanjis por menú. Si seguimos con mi cálculo bestia, si ordenamos los menús de Kanjis para que salgan ordenados según frecuencia seguramente encontremos el Kanji deseado en la posición 8 del menú como término medio. Lo cual quiere decir que para escribir un Kanji necesitamos pulsar 8(acceso al menú)+1(teclaき)=9 teclas en total si usamos un teclado Kana y 8(acceso al menú)+2(teclas “K” e “I”)=10 teclas en total si usamos un teclado occidental; que no está nada mal pero es mejorable. (Datos obtenidos usando un teléfono móvil japonés de los años 90 que usaba este sistema ancestral para la conversión Kana-Kanji).
Si a estas alturas del artículo estás totalmente perdido es porque o bien no has el Sistema de escritura Japonés, o no te interesa nada lo que estoy escribiendo, o soy yo que lo estoy liando demasiado

Hubo también cierta gente que pensó métodos para solucionar el problema rápidamente. Unos intentaron poner de moda máquinas de escribir que solo permitían introducir Kana (Hiragana y Katakana). Otros propusieron utilizar Romanji para todo e incluso los más radicales proponían eliminar el japonés e implantar el inglés. Todas estas propuestas evidentemente fracasaron, ya que el japonés sin Kanjis es prácticamente incomprensible.
La primera solución buena al problema vino de la mano de Toshiba en 1978, cuando lanzaron al mercado “el primer procesador de textos japonés de la historia”. El sistema de Toshiba era capaz de inducir con cierta precisión la conversión Kana-Kanji no solo para una sílaba sino para conexiones de varias sílabas y palabras. Lo que hacía el procesador de textos es inducir usando el contexto, la palabra que quieres utilizar y buscar los kanjis apropiados para esa palabra en un diccionario. El número de pulsaciones media para conseguir el Kanji deseado se situó entre 4 o 5 pulsaciones, si tenemos en cuenta que un Kanji se corresponde con una sílaba nuestra de 2/3 pulsaciones no está nada mal. Toshiba había conseguido que con un teclado de 50 caracteres(O menos) se pudieran escribir varios miles de forma sencilla.
Primer aparato de la historia con el que se podía escribir japonés de forma automática y en tiempo “finito”.Veamos un ejemplo del funcionamiento del procesador de Toshiba, que es muy parecido a los sistema actuales (IME en Windows, Canna en Unix y Kotoeri en MacOSX). Supongamos que queremos escribir “KIWOTSUKETE” (¡cuídate! en japonés), con nuestro alfabeto como podéis ver lo podemos escribir con 11 pulsaciones. En Japonés en cambio sería “気を付けて”, para conseguirlo he pulsado 11 teclas que corresponden con las mismas que he pulsado cuando he escrito KIWOTSUKETE, al pulsar las 11 teclas me aparece “きをつけって” en pantalla que sería el Hiragana correspondiente, algo sencillo para el ordenador porque simplemente hay que “mapear” cada Kana con su pronunciación correspondiente. La magia viene cuando pulso ESPACIO y “きをつけて” cambia por “気を付けて”, ¡han aparecido dos Kanjis! que el ordenador ha tenido que escoger entre varios miles. KI ha sido cambiado por 気, WO->を, TSU->付, KE->け, TE->て. Al final de la operación pustamos ENTER para aceptar la conversión.
Escribiendo “気を付けて” con 12 pulsaciones “K” “I” “W” “O” “T” “S” “U” “K” “E” “T” “E”) + ESPACIO(para convertir de Kana a Kanji) + ENTER (Para confirmar que la conversión es la que tu quieres). En total he pulsado 13 teclas para generar la frase deseada usando los símbolos deseados.Nota: en los videos me equivoco y escribo 気を付けって en vez de 気を付けて.
¿cómo ha decidido que esta era la transformación correcta? Por ejemplo KI puede convertirse en más de 50 kanjis diferentes, y KE también, podría haber sido 帰を付けて, 期を付けって, 樹を樹けて… y así podría pasarme horas escribiendo los varios miles de combinaciones de caracteres Japoneses con los que se pueden escribir la pronunciación “KIWOTSUKETE”.
En este vídeo muestro muchas de las varias formas que hay de escribir KIWOTSUKETE con Kanjis que va visualizando el sistema Kotoeri en el sistema operativo MacOSX. Para ello voy pulsando la tecla ESPACIO repetidas veces.¿Cómo hace magia el procesador de textos de Toshiba y los sistemas actuales para acertar con la transformación correcta a la primera? Lo primero que se nos vendría a la cabeza para hacer un sistema parecido consistiría en introducir un diccionario de japonés entero en el ordenador, y una gramática del idioma japonés. De esta forma podríamos ir cortando trozos de KIWOTSUKETE, ir procesando con la gramática para decidir las palabras(nombres-verbos-partículas…) que hay, y a continuación ir buscando en el diccionario las palabras con más probabilidad de ser utilizadas. Problemas: un diccionario de japonés tienes cientos de miles de palabras, una búsqueda con los ordenadores de la época era muy costoso; la ambigüedad que surgue usando una gramática es demasiado alta y se equivocaría mucho.
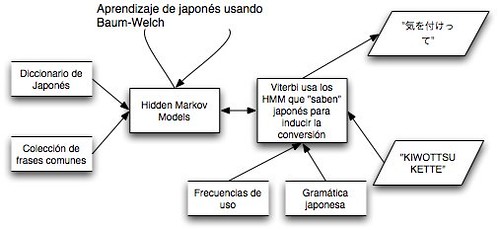
La verdad es que aunque se lo curraron mucho no hubo ningún iluminado en Toshiba, el desarrollo de la ciencia de la computación en los 60-70 fue la clave. En concreto se avanzó mucho en métodos bayesianos con los que se podía hacer “aprender” a una computadora. El objetivo pues, era enseñar japonés a los ordenadores. En concreto una “cosa” llamada Hidden Markov Models fue la clave para una revolución en el sector del procesamiento del lenguaje. Con Hidden Markov Models, un ordenador puede aprender a reconocer patrones después de haber sido entrenado usando diccionarios, gramáticas, frases y otras cosillas según el uso que se le quiera dar. Para enseñar a un ordenador Japonés usando Hidden Markov Models eran necesarias varias semanas de procesamiento usando un algoritmo llamado Buam -Welch, pero una vez aprendido el sistema era capaz de decodificar-detectar-inducir patrones prácticamente en tiempo real usando el algoritmo de Viterbi.
La clave para que esta paranoia funcionara está en que Viterbi es muy muy rápido y necesita poca potencia computacional, es un algoritmo típico dentro de la Programación dinámica. Además de ser muy rápido, si los Hidden Markov Models se entrenan bien con buenos diccionarios etc, Viterbi acierta en la conversión en un 98-99% de las ocasiones para palabras, un 95% de las ocasiones para frases cortas y un 90% para frases largas e incluso párrafos.
Esquema general y MUY simplificado de como funcionaría la conversión de KIWOTSUKETE a 気を付けて en cualquier ordenador o dispositivo electrónico actual basados en la idea original de Toshiba. En el primer vídeo que he puesto en este artículo cuando presiono la tecla ESPACIO es cuando se pone en marcha el algoritmo de Viterbi.Las primeras aplicaciones con éxito de los Hidden Markov Models se hicieron en el sector del reconocimiento automático de voz , pero pronto se empezó a ver su potencial en otros campos. En Toshiba fueron los primeros en aplicarlo a la escritura de japonés, pero pronto muchas otras empresas japonesas como por ejemplo Canon empezaron a copiar las ideas de Toshiba y a crear procesadores de texto CJK(Chino-Japonés-Coreano) y máquinas de escribir electrónicas que triunfaron en el Asia de los años 80.
Muchas empresas japonesas se concentraron en crear más aplicaciones a partir de la tecnología base. A partir de ellas se crearon los primeros correctores ortográficos no solo de japonés sino también de inglés, Microsoft más tarde contrataría a muchos japoneses para crear un laboratorio de procesamiento del lenguaje. El corrector de vuestro Microsoft Word también usa Hidden Markov Models de una forma algo diferente, pero al fin y al cabo es más de lo mismo.
Un ejemplo, de como ante la presión de unas restricciones a las que se estaba viendo sometida la sociedad y los idiomas asiáticos ante la llegada de nuevas tecnologías supieron ser creativos y buscar una solución que no solo le sirvió a Japón y al japonés sino a todo el mundo. ¡Cuando escribes usando el modo diccionario con tu teléfono móvil estás usando tecnología japonesa cuyas bases se asentaron en los años 70! y sin olvidar a Andrei Markov que hace más de cien años desarrolló la base matemática.




Interesantisimo post de Kirai sobre el sistema de escritura japones para moviles.
Ahora que estudio el idioma me lo preguntaba con mis compañeros de clase, el como podian escribir si habian tantas variantes para un mismo sonido. Lo mismo me ocurria en clase de chino. Una vez más, la sabiduria se obtiene al convivir con una cultura y buscar un poco de información extra. Gracias Hector^^ No puedo esperar a saber más con la segunda parte^^
Technorati Tags: Japones, escritura , kanji, moviles, japan, mobile,
Etiquetas: Japonés
entrada de Getres a las
lunes, noviembre 13, 2006
![]()
![]()


0 comentarios:
Publicar un comentario
Suscribirse a Enviar comentarios [Atom]
<< Inicio